Deep Learning, xgb, BERT Flashcards
Intuitively, why should a NN/MLP with a bunch of successive layers of processing be good at finding patterns, like identifying images of digits?
The intuitive idea is that each subsequent layer is being trained to recognize higher-level patters. So maybe layer 1 is edge detection, layer 2 is finding a shape like a circle, and layer 3 can identify full digits.
In a more complex image, maybe layer 1 is lines, layer 3 is texture, etc.
In a “vanilla NN”, or MLP, how does a given layer of processing work? How do we go from layer i of size N to layer i+1 of size M?
Each of the M neurons in the output layer is computed by taking a weighted sum of all the values of the input layer (plus a bias), then passing it through an activation function. Typically the weights are learned but the activation is not, it’s something like relu or sigmoid.
So in order to get one of the output neurons, you take the N inputs, plus an input of 1 that’ll be multiplied by the bias, as a column vector and multiply them by a length N+1 row vector of weights; then you take the that output and pass it through the activation.
So if you want a length M output, you need M row vectors, and thus you’re multiplying the length-N+1 input by an MxN matrix to get the length M output (which goes through the activation).
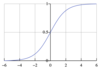
What is the sigmoid activation? What is its formula, and what does the graph look like? What does it functionally “do”?
It squishes all the real numbers between 0 and 1, like in logistic regression.

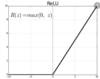
What does the relu activation function look like?
What is the softmax function? How is it computed, and what is it used for?
The softmax is the go-to output layer if you’re predicting a categorical variable with more than 2 categories. All the layer outputs are between 0 and 1, and they sum to 1 – so they’re basically probabiltiies, and whichever outcome class is being predicted as having highest probability is chosen.
The formula is shown below, where there are K values you’re trying to predict, each has a corresponding value z that needs to be passed through the softmax.
It’s similar to sigmoid

What gradient are you calculating during optimization, and why? How does gradient descent work?
In order to optimize a neural network, you need to find the derivative of the loss function with respect to each of the weights in the network (maybe thousands or millions), and then you update the weights by taking a small step in that direction (I think technically the opposite direction but whatever).
If you want the partial derivative of a function with respect to each input variable, that’s the gradient: the gradient of the loss function is the vector of the function’s partial derivatives with respect to each parameter. So that’s what we calculate and optimize based on.
Conceptually, how does backpropogation work?
New simple and valuable thing to remember: The chain rule is just dy/dx = dy/du*du/dx, so it makes sense that dLoss/dSecondLayer = dLoss/dFirstLayer * dFirstLayer/dSecondLayer. And that shows clearly how gradients are based on past ones, and are eventually long chains of multiplied gradients (which could lead to vanishing gradients)
Basically you use the chain rule to efficiently get the partial derivatives one layer at a time.
You start by setting up the formulas to get the partial derivatives of the loss function with respect to the weights in the last layer. **These formulas will depend on the activation of the previous layer**, but you just hold that value constant while simply calculating the partial derivatives of this layer.
Then, basically using the chain rule, you substitute in the formula for the activation from the previous layer, and now holding constant the stuff from the subsequent layer, you simply calculate your next round of partial derivatives.
Then repeat, because the now the formula is dependent on the activation of the previous layer, which you can again substitute in, etc! I’m not gonna get totally into the weeds memorizing the exact math
What is one-hot encoding? Why is it needed for neural networks?
Basically if you have a categorical variable with N>2 outputs, you’ll represent each row’s value of that variable wth N columns, each pertaining to one of the N categories. There’ll be a 1 for the category in that row, and 0s otherwise
You need to one-hot encode because NNs need numerical inputs, so they can do computations by multiplying input vectors by weight matrices, and use derivatives of numerical formulas to optimize.
Why is the activation function important?
Without a nonlinear activation, you would just be learning a bunch of complex weighted sums of the inputs; it would be all linear. Nonlinear activations let you learn nonlinear relationships, which is where the magic happens.
How are log loss and cross entropy loss related? How do they work?
New:
Remember the specifics here: it’s the sum of the negatives of isCorrect*log(predictedProb) for each class.
So a term only has weight if it’s the prob for the correct label (I had misremembered it as all the other ones have weight, not that one.)
And log(1)=0, log(decimal) = big negative number. So if you predict low for the truth, you get a big negative log value, then take its negative to get a big positive loss, as desired.
I’m confident this is the case.
Original:
Log loss (also called binary cross entropy) is for a binary categorical and cross entropy is 3+ outcomes, but they’re basically the same thing; it’s like sigmoid vs softmax.
These loss functions are just using negative log likelihood. So we are trying to find the maximum likelihood estimation of the best parameters: we try to find the parameters such that “the likelihood that those parameters, and the associated probabilties they yield, would have resulted in this dataset” is maximized.
So like, when we’re predicting a categorical variable, our model’s output is a bunch of probabilities. We want to get those probabilties close to being 1 for the correct answer and 0 for everything else, because that is the maximum likelihood solution: those are the probabilties that are most likely to have yielded this label, and thus the parameters associated with that probability are most likely to yield that label.
What’s the formula for log likelihood, aka binary cross entropy?
Hopefully this isn’t that important to memorize if you’ve got the concept

What final activation is typically used, and what loss function is typically used, for predicting a binary categorical variable?
What about a categorical with 3+ options?
Activation is sigmoid, loss is BCE.
For 3+, activation is softmax, loss is cross entropy.
Why is it important to normalize all of your input columns?
So all of the input columns have the same scale, making it easier to learn at approximately the same rate (and using the same learning rate parameter) for each input.
If one col had a really big scale and another had a really small scale, then a step that’s as large as the learning rate will be hard to get right for both columns: you might have a too-big step for the small-scale one, and vice versa.
What is the learning rate?
When would you decrease the learning rate? When would you increase it?
The learning rate is a positive scalar that determines how large of a step you take in the opposite direction of the gradient each time you take a step.
You would increase it if you’re learning too slowly, and decrease it if you’re underfitting or if your learning is jagged.
What is dropout regularization? Why does it work as a regularization tactic?
Dropout regularization is when we give nodes in the network a probability that they will be turned off on a training pass. So each time the model is run during training, we look at each node that might turn off, and if we pull the appropriate random number, set it to zero for this training run.
So for every training evaluation, we’re using a random subset of the nodes; the other nodes, and by extension their incoming and outgoing connections, are removed. (We don’t do dropout during validation or testing.)
My intuitive understanding of why it works for overfitting: first of all, it on average decreases the size of the model during training, and smaller/less complex models overfit less.
Also, because the model cannot consistently rely on having a specific node on a given run, it’s harder to, say, encode in one specific training point’s outcome variable in one specific node. Like if for example the model were trying to encode each training point’s individual outcome variable using one node each, that wouldn’t work super well with high dropout.
What causes vanishing gradients in neural networks, especially deep neural networks?
Certain activation functions have areas where their derivatives are very near zero: for example, the extreme values of sigmoid. So if all or most of the neurons get to the extreme values of sigmoid, the gradients will have a lot of very-near-zero values, which causes very slow training.
This is exacerbated by the fact that derivatives in NNs are often basically the the product of several of these individual derivatives, chained together by the chain rule. So you’ve got a bunch of near-zero values multiplied together.
Intuitively, why does using the relu activation function combat vanishing gradients, and exploding gradients?
A derivative in an NN is usually a bunch of individual derivatives of the activation function multiplied together, because of the use of the chain rule in backpropogation.
If the activation derivative tends to often be less than 1 (as with the extremes of sigmoid), these derivatives will tend to zero, and vanish. If they often to be greater than 1, they will tend to infinity and explode.
But the derivative of relu is always either zero or 1. So the product of a bunch of the derivatives will be either zero and 1, but some of them will typically be 1, because the network will need some info flowing through for each point. So there are usually always some gradients that aren’t vanishing and aren’t exploding
How do you get the best of both worlds of normal gradient descent and stochastic gradient descent
Stochastic batch gradient descent: take a step every batch of k datapoints, rather than every 1, or just every epoch. Super common
Why is learning rate decay useful?
Usually we want to take large steps at the beginning and slow steps at the end: at the end we’re near a local minimum and just want to slightly refine, where as at the beginning we probably have quite a ways to go.
How does momentum work, and what purpose does it attempt to solve?
In momentum, rather than taking a step in the direction of the current gradient, you take a step in the direction of an exponentially decaying weighted sum of all past gradients.
The hope is that it helps you “power through” local minima to reach global minima. So for example, if you got to the bottom of this local minimum, the current gradient would be zero, but the previous ones are still pointing right and would carry you through.
Momentum is also helpful because it helps decrease jagged training (see the wide and shallow concentric ovals visualization you’re familiar with here: https://towardsdatascience.com/stochastic-gradient-descent-with-momentum-a84097641a5d)

What little optimization can often be made to the pairing of softmax output and cross entropy loss?
Rather than having softmax output probabilities, have it output the logs of the probabilties, and alter cross entropy to recieve them. As we know, optimizing based on the logs achieves the same optimization, and is often more computationally effective.
What is a good default approach to randomly initializing the weights and baises of an NN?
Init biases to zero; this is just super common.
Weights: when choosing outgoing weights from a layer with n nodes, we sample weights from a normal distribution with mean zero and stddev 1/sqrt(n)
The general idea is to have the weights inversely proportional to the # of nodes in the previous layer, and thus inversely proportional to the number of weights.
Intuitively, we can say that by doing it proportionally to the number of nodes that are feeding into the next layer, the inputs to the next layer aren’t too big or small, and they aren’t really dependant on the # of weights. But this is super hand-wavey, so I feel fine basically just saying “experimentally, this works really well.”
Name an application that would use a many-to-many, many-to-one, and one-to-many RNN architecture
many-to-many: language translation
many-to-one: sentiment analysis
one-to-many: text generation with a starting word as a seed
There are 2 big reasons you wouldn’t want to use a normal NN for text inputs, and RNNs solve them. What are they?
The input text is variable length, but normal NNs have an input layer of fixed length
A normal NN would learn different weights for the beginning and end of the sentence, even though there can be shared info (similar to a CNN): the phrase “Harry Potter” is a name whether it’s at the start or end of a sentence.
How does a basic one-layer RNN work? What 3 sets of weights are learned, and how are they applied to an input?
An RNN has a common “structure” or “hidden layer” that is applied sequentially to each time step in the input structure; for example, words in a sentence.
At each application, there are basically 2 things that determine the activations ‘s’ of the hidden layer: the input, and the weight matrix Wx that connects the input to the hidden layer; and the activations of the previous application of the hidden layer, and the weight matrix Ws that connects the previous activations to the hidden layer. The two matrix-vector products are calculated, summed, and passed through the activation function.
Then, a third matrix is learned which connects the activations of the hidden layer to the output layer. (Then maybe there’s an activation like sigmoid.) Depending on the architecture, this might be evaluated at every step, or at just the last step, etc.
Here are 3 different ways of showing the same basic network; the first shows the key formulas.
In what sense does an RNN have “memory”, and why is it useful?
RNNs use the activations of the previous layer to figure out the activations of the current layer. This is useful for using context: if the last two words were “throw the”, the next word might be “ball”; if yesterday’s stock price was high, odds are it’ll be high today too.
What can we learn from the Elman Network representation of an RNN to better understand how information flows through the network? In what sense can Wx and Ws be thought of as one matrix? I just love this representation, it’s so intuitive and actually explains the architecture: remember it!

In an RNN, both the input vector x and the previous activation vector s are multiplied by their own respective weight matrices to get new vectors of the same length, which are summed to get the final value. This is where the formula activation([Wx]*x + [Ws]s_t-1) comes from.
But this is not actually that weird, because it can just be thought of as x and s_t-1 being lined up into one vector and multiplied by one weight matrix!
How would an RNN have “multiple layers”, such as if it had 3 layers?

If you’re confused, think about it in the Elman diagram way again.
It’s pretty intuitive: the first layer recieves the input and the first-layer activation from the previous iteration. Similarly, the nth layer at time step trecieves the activation of the n-1st layer at time t, and the activation of the nth layer at time t-1.
Sometimes each layer has the same weight matrix, except specific ones for the first input and last output. Other times it’s different and there’s fewer shared matrices.
What is the algorithm called to optimize an RNN?
Backpropogation through time
What is an intuitive explanation of backpropogation through time?
We need to update 3 weight matrices: Wy, Ws, and Wx. So we need to find the derivative of the loss function with respect to each matrix (or the derivative w.r.t ecah of the parameters within each matrix).
Because some matrices are called more than once in the chain of dependencies, we need to go back in time and encorporate all of those calls.
The key is the chain of dependencies. So if we’re looking at the loss function at time step 3, the y matrix Wy (which connects the hidden layer to the output) only has one invocation in this particular dependency chain for this time step, so the computation is easy. But if we’re looking at Ws or Wx, each of those was used at 3 separate times in the past, so we need to find the derivative factoring in each of those invocations using the chain rule.
How is an RNN optimized using backpropogation through time?
Specifically, say an RNN with length-n input has a length-n output. For a single input x, how is each weight matrix updated based on that output and its parts?
How is this different if there’s just one output at the end, as with sentiment analysis?
(I’m pretty sure the following is true)
If a single input has n outputs, that’s basically n instances where the loss function can be calculated and backpropogation can occur.
So if there’s 3 outputs, the first output will be used to update Ws based on one invocation; the second output will again be used to update Ws based on 2 invocations; and the 3rd uses 3 invocations. And similarly for Wx; Wy always only has 1 relevant invocation in the chain of dependencies.
This makes sense: if we have n outputs, such as if we’re labeling POS for the words in a sentence, we basically have n unique predictions, so even if it’s just one input in a sense, we have n opportunities to learn and improve our predictions.
Now I’m sure that, rather than updating the weights after each of these, you could instead accumulate the gradients, average them, and then make an “aggregate update”, similar to how with batch gradient descent you store a few individual-point gradients, average them, and take a step.
Can you use batch gradient decent to combine a few input x’s together?
Yes
What is a big problem with normal RNNs? How does it happen, why is it bad, and how can it be combatted?
Vanishing gradients lead to “bad long-term memory”. Basically, when we’re trying to update Wx or Ws based on the output at a very late time step, we find the derivative of the contribution of that matrix W from all previous time steps.
But the derivative for early time steps is a lot of derivatives chained together, leading to vanishing gradients. So when we’re updating based on a late outcome, the contribution of an earlier part of the input vanishes. This can be bad: words at the beginning of a sentence can have a big impact on the meaning of the end of the sentence, for example.
It’s intuitive that vanishing gradients are especially bad for RNNs: they’re bad when a bunch of layers are applied in a row, because all of the potentially small gradients are getting multiplied together. Well, an RNN has a layer that can easily be applied 50 or 100+ times if the input x has 100+ time steps.
The solution is LSTMs
RNNs also suffer from exploding gradients. What is a simple and effective way of combatting this?
“Gradient clipping”: just penalize the network for creating gradients above a certain threshold
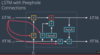
At a high level, what new functionality do LSTMs add on top of normal RNNs?
Long term memory! RNNs have a mechanism for using short term memory, but due to the vanishing gradients problem, they can’t really effectively retain info from very long ago. LSTMs add a path to pass along and retain long term memory in addition to the short term memory pathway.
I’m not gonna get into memorizing gates and architecture and stuff; as Dr. Kolter said, a lot of that is hand waving. There are 4 “gates” for bringing in and interpreting old and new information, and reforming it into new long and short term memories.
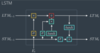
Where does the output/prediction of an LSTM cell come from, if applicable
It is based on the newly updated STM. Perhaps the actual new STM could be output, or I imagine there are often learned weights that transform it a bit to form a y. Like the STM is probably often a vector of key STM info, whereas the output might be a prediction of the next word or something.
What is the general idea of LSTM cells that use peephole connections?
The peephole connections basically allow the cell to make more heavy use of the previous LTM by inserting it into more locations.
What is an example of a sentence where long term memory would be important for understanding a later part of the sentence?
Perhaps, for example, there is a verb late in the sentence, and the subject of that verb came way earlier in the sentence.
“The cat, which already ate at about 4pm and quite enjoyed their wet food, was full.”
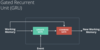
GRUs are kind of a variant of LSTMs. How do they work at a high level?
GRUs only have one memory vector flowing through, rather two for a separate LTM and STM, as with LSTMs. In this way, they look much more similar to normal NNs.
But unlike normal RNNs (which basically only have one simple gate that passes the concatenated input-and-previous-activation through 1 layer of an NN), GRUs have 2 gates. These gates work to decide which “memory cells” in the previous cell’s activation should be overridden with new information, and which should be retained as a sort of long term memory. This allows the system to learn to maintain certain pieces of information for an arbitrary period of time.
If you think GRUs are gonna be important to understand, you could rewatch the coursera video on them to better understand how they work and make updates at a low level.
What are two potential uses of an RNN which, at every step t, tries to predict the next value in the sequence, X_t+1?
Writing new text, either one word at a time or one letter
Time series prediction: predicting stock prices or something
If you’re training an RNN whose prediction at time step t is “what’s the value of the input at time t+1”, how do you construct the outcome variable? Why does this construction avoid letting the RNN use the outcome variable when predicting the outcome variable?
You construct the outcome variable as you would intuitively: you just shift the input over by one and have that be the outcome variable
The reason this isn’t “cheating” is for this type of RNN task, we’re just using a feed-forward RNN rather than a bidirectional RNN. So at any given time step t, the only information available to the RNN to make predictions is the inputs at time steps t and earlier. So there’s no cheating
The RNN is evaluated sequentially. So it makes the t=1 prediction, then a gradient is found; then it does t=2, and gets another gradient; and so on
How are training inputs and batches formed for an RNN? Say for example we’re training a character-level RNN to predict the next character in a sequence.
One option is sequence batching.
Say our input is an entire book (visualized below by 12 letters). First we split it up into N sections, and then we split each section into sections of M letters.
A batch is then a set of M letters from each of the N batches. Below N=2 and M=3; our first batch is [[1,2,3], [7,8,9]], and our second is [[4,5,6], [10,11,12]].
If you wanted to simplify this, I imagine you could just split the whole input into length-M segments and then make every N of them a batch, but not split into N sections like this. That’s also conceptually simpler, and perhaps a good way to start thinking about it.

Can you use dropout in RNNs?
Yep! It works for any of the relevant weight matrices.
If you’re making an RNN over a sequence of letters to predict the next letter in the sequence, what exactly is the prediction output?
What about if you’re predicting at the word level?
A probability distribution showing the odds it’s a given letter.
If you’re predicting words, I’m pretty sure it’s the same thing: you make a probability distribution showing the odds it’s each of the words in the vocabulary, and you would calculate error vs the one-hot vector for the correct answer.
My other thought was maybe you output a word embedding and compare it to the word embedding of the correct answer, and then at prediction time you like output the word that is closest in the embedding space to the embedding vector you predicted. But I just don’t remember that being a thing: I think you just choose the maximum-lihelihood word from a probability distribution you’ve created, or you sample from the probability distribution if you want some randomness.
When training a character-level RNN using sequence batching, over what intervals do you backpropogate through time? Is information passed and/or does backpropogation occur across multiple sections, or multiple lines?

Backpropogation only happens within each little stretch. So in this diagram there would be 4 instances of backpropogation.
But there is still information communicated across the blocks within each line. When the network predicts on the input 4, it recieves the activations of the RNN cell from the previous input of 3, and that information is passed across batches. It just doesn’t backpropogate all the way back through multiple batches; otherwise the chain would get insanely, unproductively long, and training would take a long time.
There is no info communication or backpropogation across lines.

Do all of these low-level implementation details for character-level RNNs, with predictions every time step, apply to all RNN architectures and applications?
No! Each application is gonna have its own idiosyncrasies with how data and batches are best divided up, how the model is constructed, how the training loop works, etc. To implement the best thing for a given application will take experience implementing RNNs, as well as experimentation to see what gives the best results.
What are word embeddings?
A set of word embeddings is a mapping from each word in your vocabulary to a vector of a fixed length, say 768 (much shorter than your vocab size), where each word’s embedding contains meaningful information about the word’s meaning, its grammatical function, its relationship to other words, etc.
What is one potential danger of word embeddings?
Retaining the biases of the training data. For example, the embedding for “homemaker” might be closer to “woman” than “man”. Debiasing strategies become important for this reason.
What are 2 big advantages of using word embeddings over just the one-hot encodings of the words?
- It significantly reduces the dimensionality. Training is inefficient with one-hot because, if the input vector has one 1 and thousands of zeros, very few weights are lit up and thus are optimized per input.
- They learn semantically meaningful information. They learn that “sandwich” and “hoagie” are similar, so the learning from one can immediately apply to another. That’s better than having to relearn similar weights coming out of the node for sandwich and the node for hoagie.
Generally speaking, how are word embeddings learned?
In an unsupervised way, from a large and general text corpus like the set of all wikipedia articles.
How are word embeddings included in an RNN?
You put the word embedding layer between the input and the “main RNN cell”, so from the perspective of the cell, the embedding is the input. If you’re learning a custom embedding scheme while training the RNN, you can have backprop-through-time go through the embedding layer.
(In this picture sigmoid just refers to an FC layer with a sigmoid activation)
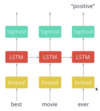
How might attention be used if the encoder is interpreting an image, and the decoder is writing a text description of that image?
The decoder figures out where in the image is relevant to the particular part of the description it’s currently writing. Awesome.

How does a bidirectional RNN (or LSTM or whatever) work for an example task like named entity recognition?
It’s pretty simple: there are basically “2 RNNs”, one that iterates over the input from front to back, and another that goes from back to front. So 2 hidden states are learned for each input: one that uses that input and all the earlier context, and another that uses that input and all the later context. Then both of those hidden states are concatenated and passed through a single dense layer to get the prediction, which in this case is the probability that a word is a name.
How does a convolutional layer work in its most basic form? Say we have a square input greyscale image, and we’re applying a single convolution to it with dimension 3x3. How would the next layer be calculated?
The convolutional layer is going to have a convolution, or ‘filter’, which is a 3x3 array of learned weights. To perform a convolution, you apply it to a part of the grid by multiplying the pixel values by the corresponding weight, then summing the results, and then passing the sum through an activation function.
You do that for all parts of the image (depending on stride and padding and such, but ignore that for now): you scan across the image continually applying the convolution to form the output of the layer, which is still square.

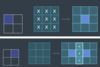
If you’re trying to have an application of the convolution centered at every pixel in the input image, handling the edges gets weird: with a 3x3 convolution, if you’re on an edge, there will be parts of the image with no input pixel to multiply?
What are three ways this can be handled? What is the most common?
I’m pretty sure the most common is padding. It feels common.

How is a convolution applied to an RGB image? What shape would the filter be, and how would the resulting output be calculated?
An RGB image has 3 channels, so its shape is something like (28,28,3).
In a normal 28x28 image, we’d have a filter like a 5x5 array of weights, and we’d apply it at a point by multiplying the weights by the corresponding pixels, summing all the resulting numbers, and passing through an activation.
The RGB case is similar, except now the filter is 5x5x3. The height and width can be whatever, but the depth of the kernel will equal the depth of the image, so we can learn about each of the input channels. This way we basically have three 5x5 kernels being applied to the image: one to the red values, one to blue, and one to green. Then all 5x5x3=75 results are added together, across all 3 channels, and then passed through an activation function.
So conceptually, an edge detector could learn how to detect edges separately in each of the 3 colors, having one detector for each color. For example.
Below is a great image.

Suppose an input is of shape (28x28x3) (as with an RGB input image), and we want the output of our convolutional layer to be of size (28x28x4). Don’t get bogged down with getting the output 28x28 part right, and focus on the 4.
How would this work? Describe what weights the convolutional layer has, and how it applies them to get the output with a depth of 4.
Say we use a 5x5x3 filter, and we pad the image such that with a stride of 1, the outcome will be 28x28x_. What will the depth be?
Well we scan the width and height of the image, and at each point we apply our “three separate 5x5 filters” to the three channels, sum the 75 outputs across all 3 channels into one scalar, and pass through activation. So we’re getting one scalar at each point. That means the output is depth 1: 28x28x1.
So how do we get 28x28x4? We learn 4 different, separate 5x5x3 filters. Each will result in its own 28x28x1 output, yielding a 28x28x4 output.

Why would we want to have a convolutional layer whose output depth is higher than 1? Why would we wanna have, say, 5 different 5x5x3 filters to apply to a 28x28x3 RGB image, so the output dimension is 28x28x5?
Each filter can learn something different about the input! Maybe one detects edges, one records how bright it is, one checks if the dominant color is red, etc. Or maybe they just all detect different types of edges. One filter can only really learn one thing, but using multiple allows us to learn more complex and varied information during each layer.

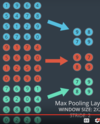
How do max pooling layers work? How would a 2x2 max pooling layer be applied to, say, a 28x28x3 input, and what would the output size be?
How does the less common average pooling layer do this?
A 2x2 max pooling layer will decrease the height and width of an input by half, so the output will be 14x14x3.
It does this simply enough by, within each channel, looking at each 2x2 grid within the channel, and outputting the max of those 4 values.
An average pooling layer does the exact same thing, but instead of outputting the max of the 4 numbers, it outputs their mean.
What would be a common construction for a CNN being used for a task like image classification. How would the layers be ordered, and what would happen to the input over time?
To start the network, there would be several blocks of one or more convolutional layers followed by a max pooling layer. Each blocks’ convolutional layers will typically use padding so the height and width of the image don’t change, and thus they only change when the max pooling layers decrease them by half.
We will continually learn more and more ‘features’, or ‘channels’, about the input as we go, so when combined with the max pooling layers decreasing width and height, we will go from a representation whose height and width is much larger than its depth, to the other way around: a very deep representation with small width and depth.
After we achieve this through several conv-pooling blocks, we’ll flatten the resulting matrix out into a 1d vector, and pass it through a few simple dense layers before outputting our prediction.
The below image doesn’t show the dense layers at the end.

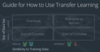
Say you’re doing transfer learning, using a big pretrained image classifier for some image classification task of your own. What might be a sensible way to handle it if:
- You have little data, and it is similar to their task?
- You have lots of data, and it is similar to their task?
- You have little data, and the tasks are not similar?
- You have lots of data, and the tasks are not similar?
Little and similar: you can use most of the layers and can’t do much retraining, so maybe just replace a couple of the fully connected layers at the end, leaving all the layers before it fixed and not backpropogating through them
Lots and similar: because you have lots of data, you should still fine-tune the architecture, but the parameters learned from the similar task are a good initialization. You’ll of course swap out a layer or two at the end (as with any of these cases) just so your # of output classes is correct
Little and not similar: Here, overfitting to our small dataset is still an issue, so we will hold the parameters from the original network as constant. But now because the datasets are different, task-specific features that the original network learns in later layers will not be useful. We can, however, still use the more abstract features from earlier layers, like textures and edge detection. So we remove most of the original layers, leaving only the beginning layers that extract more general image features. Then we add a few new layers and only backpropogate through the new ones.
Lots and not similar: you might fine-tune the parameters from the original, or you might just totally retrain it and just use the original network’s hyperparameters, like number and size of layers, as a starting place.
How do autoencoders work? What task are they trying to accomplish, and what architecture do they use to accomplish it? What is the loss function?
Autoencoders are a compression algorithm, or a learned means of dimension-reducing an input, then scaling it back up to its original size with as little lost information as possible.
An autoencoder is basically a neural network made up of two sub-neural-networks: the encoder and the decoder. The encoder takes the input and maps it to a low-dimensional representation, and the decoder takes that low-dimensional representation and maps it back up to the original size of the image.
That low-dimensional representation in the middle there is the compressed form, and the goal of the network is to get that as good as possible. The loss function is simply to compare the input to the reconstructed input: if the input was an image, you just find the pixel-level MSE between the two, so the network aims to make the output as similar to the input as it can.

What are a few applications of autoencoders:
Compression obviously: one computer could store the trained encoder, and the other could store the trained decode, and then they can send the low-dimensional representations from one to another.
Denoising, which is so goddamn cool and shown below. By just storing the most “semantically meaningful” information about the input, you can drive away meaningless noise, which is good for denoising.
Similarly, image reconstruction: if a little sliver of an image is missing, an autoencoder can fill it in

Without getting into the weeds (I’m not concerned with the lowest-level math), how do transpose convolutional layers, or “deconvolutional layers”, generally work, and what are two potential applications?
In autoencoders, the decoder needs to take a low-dimensional vector and upsample it into an image. Similarly, in a GAN generating images, then generator needs to take a small vector of noise and upsample it into an image.
These networks start to look like reverse CNNs: CNNs slowly go from large height/width and few channels to small height/width and many channels.
So these upsampling networks need to do the opposite, slowly increasing the height and width. This is what reverse convolutional layers do: they basically apply a filter which is larger than the area it’s being applie to, and doing so with a high stride like 2, so the output height and width are larger than the input’s.
What is a global average pooling layer? How does it work, where might you include it in a CNN, and what purpose does it serve.
A GAP layer, if included, would be included after all the blocks of conv/pooling layers, before the fully connected layers.
It is basically an extreme version of a pooling layer: it maps every channel to one scalar, which is the mean of all the values in the channel.
Often, the inputs to the dense layers are so large (so many channels of substantive height and width), that there are just too many parameters in the final dense layers, which can cause issues with overfitting. This is a way to combat that overfitting: it drastically decreases the size of the input to the dense layers, thus decreasing the number of parameters they need to have.
Because of the nature of conv layers vs dense layers, oftentimes most of a network’s parameters can be in those final few dense layers, so this can be a very effective way to decrease the # of params and combat overfitting.

We’ve already covered that momentum can be used to “power through” local minima in order to hopefully reach other minima that are lower.
What is another potential advantage of using momentum during gradient descent? In what situations will this advantage be present, and how will momentum achieve this?
Because it takes an average of all previous gradients, with a focus on recent gradients, it can smooth out learning if it happens to be jagged. If the gradients keep jumping back and forth in one of the dimensions, those will average out to about zero, and the descent will stop taking big steps in those dimensions and focus on the dimensions with a consistent direction.
This is illustrated in the following picture. These are contour lines, and each line is at a constant level in the z direction with respect to itself. So this means the slopes are way more steep in the y direction than x, because height is changing over a much smaller horizontal distance. This may be easier to see if you envision it as maximizing over a hill rather than minimizing over a valley.
So in this context, you can see (in blue) how the baseline slopes will be much larger in the y direction than x, causing most of each step to be a jagged movement in the y direction rather than a productive movement in the more subtle x direction. Momentum (in red) smoothes this out. (The red drawing over-exaggerates the size of the steps in that direction, but it’s just meant to illustrate how the jagged y-direction movement is decreased.)

What is the goal of the RMSprop optimization algorithm, and how does it work intuitively?
The goal, similar to momentum, is to combat jagged and inefficient learning by smoothing out our steps in the direction of the gradient.
The general idea of RMSprop is it keeps track of which dimensions keep having large steps and which keep having small ones, and uses that information to smooth out training by decreasing the relative size of the large ones and increasing the relative size of the small ones.
It does this by dividing the size of the step in each direction by a weighted average of recent derivatives in that direction.

How does RMSprop work at a lower level?
Again, the goal, similar to momentum, is to combat jagged and inefficient learning by smoothing out our steps in the direction of the gradient.
In momentum, you keep a exponentially decaying weighted average of the gradients, and each iteration you take a step in the direction of that weighted average.
In RMSprop, you instead keep an exponentially weighted average of the squares of each of the partial derivatives, and then to construct the “gradient” which is the direction you want to move, for each dimension you take the current partial derivative, and divide it by the square root of the exponentially decaying sum of the derivatives.
That’s pretty complicated, but here’s the intuition: because we’re squaring the derivatives in the sum, they’re always positive; so the bigger the past derivatives, the bigger the value by which we’re dividing the size of our current step. Steep dimensions where learning is jagged will have large gradients, so we’ll be dividing by a large value and decreasing the size of the step; conversely, not-steep dimensions with slow learning will now have relatively larger steps, so we make proportionally more progress in that direction. This can be used to increase the learning rate, and overall learn faster.
The key parts of this picture are the top, showing the image where each fault like has a consistent height and thus the y axis is much steeper, and the bottom, showing how the update is the derivative, divided by sqrt(weighted sum of squares of derivatives).

How is batch normalization implemented?
Basically how it’s explained: subtract the batch’s mean and divide by its variance.
The only deviation from this is that we actually add a small epsilon to the variance in practice. This is partially to avoid a variance of zero, and partially because we’re really trying to estimate overall population variance, which is typically a little higher than a batch’s variance.
