Formulas etc Flashcards
Prevalence of disease
of cases/# of people observed at one time point
Risk of disease
of new cases/ # of people followed
Incidence of disease
of new cases/sum of follow up time for everyone observed
Rate
Has time on the denomintor
Incidence and mortality rate are both rates
Definition of a cause of a disease
An antecedent event, condition or characteristic that was necessary for the occurrence of the disease at the moment it occurred, given that other conditions are fixed
An antecedent event, condition, or characteristic without which the disease event either would not have occurred at all or would not have occurred until some time later
Prevalence v. incidence

Cross-sectional study
Study of exposure-disease association in which prevalent exposure and disease status are ascertained
All done at one point in time
Problems with cross-sectional study
Subject to reverse causation: because exposure & disease are determined simultaneously, not sure if your exposure causes your outcome or your outcome causes your exposure
- *Disease prevalence** rather than incidence is measured:
- excludes those who died before sampling
- selects for those with mild disease
Cohort study
A sutdy of exposure-disease association in which baseline exposure and incident cases of disease are measured among study participants who are non-diseased at baseline
Approach to analyzing a cohort sutdy
Measure incidence of disease in exposed and in unexposed
Compare these two incidence rates
Rate ratio
Incidence of disease among exposed divided by incidence of diseased among unexposed
Abbreviated as RR or risk ratio/ relative risk
If RR=1 null
If RR<1 decreased risk among exposed
If RR>1 increased risk among exposed
Risk difference
Risk among exposed - risk among unexposed
Relative v. Absolute risk
Two ways of expressing the same thing
Relative risk: risk of breast cancer among drinkers is about 17% higher than the risk among non-drinkers
Absolute: among drinkers, the riks of breast cancer is about 0.05% higher per year than among non-drinkers
Attributable risk percent
[Risk among exposed- risk among unexposed] / risk among exposed
Risk difference/risk among exposed
Population attibutable risk
(overall rate of dz- rate of dz among unexposed) / overall rate of dz
Represents % of cases that could be eliminated from the pop if the exposure were eliminated
Summary of different measures of association: RR, RD, ARP, PAR

Pitfalls in cohort studies & all observational studies
- *Bias**:
- selection bias
- information bias
- loss to follow up
Confounding
Resource intensive: years, money, career
Case-control study
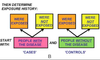
What measure of association can you use in a case-control study?
Odds ratio
Odds
Probability/(1-probability)
Odds ratio
Odds of exposure among case / odds of exposure among controls
Odds ratio = AD/BC
Note that odds ratio approximates the rate ratio when the disease is rare!!

Potential problems with case-control studies
Confounding
Recall bias
Biased selection of controls
Interpretation of the odds ratio (when the disease is not rare)
Cannot measure incidence rates
Nested case control study:
Select your cohort
Follow for those who develop disease v. not develop disease
Select your cases and controls from the two groups respectively as the study progresses
Matched on calendar time and length of follow up
Using this sampling method, odds ratios are equivalent to rate ratios
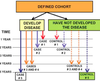
Case cohort study design
Start with a cohort, follow for those who develop disase
Select your cases from those who develop disease
Select your controls RANDOMLY (note that it means some of them could have dz!) - called a subcohort
Since controls are not matched to each case, multiple case definitions can be compared tothe subcohort
Can be analyzed as a cohort study if the sampling method is taken into account

Cohort v. case control studies

4 explanations for an observed association
True
Chance
Bias
Confounder

Adjusting for confounders
“regression models”
these can adjust for many potential confounders at the same time
dz, exposure, and potential confounders must be measured to be included in the model
each “m” is really a rate ratio or odds ratio in disguise
“m” is adjusted for all of the “covariates” in the model
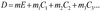
ROC curves
Receiver Operator Characteristic curves
Used for tests with continuous scale for results, such that cut off for defining + test can be set higher or lower
