Chapter 10: MapReduce Flashcards
1
Q
Origins cont’d
A
- Task for processing large amounts of data
- Split data
- Forward data and code to participant nodes
- Check node state to react to errors
- Retrieve and reorganize results
- Need: Simple large-scale data processing
- Inspiration from functional programming
- Google published MapReduce paper in 2004
2
Q
From Lisp to MapReduce - important features
A
- Two important concepts in functional programming
- Map: do something to everything in a list
- Fold: combine results of a list in some way
3
Q
Map
A
- Map is a higher-order function (= takes one or more functions as arguments)
- How map works:
- Function is applied to every element in a list
- Result is a new list

4
Q
Fold
A
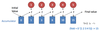
- Fold is also a higher-order function
- How fold works:
- Accumulator (generalization of a counter) set to initial value
- Function applied to list element and the accumulator
- Result stored in the accumulator
- Repeated for every item in the list
- Result is the final value in the accumulator
5
Q
Lisp -> MapReduce
A
- Let’s assume a long list of records: imagine if…
- We can distribute the execution of map operations to multiple nodes
- We have a mechanism for bringing map results back together in the fold operation
- That’s MapReduce! (and Hadoop)
- Implicit parallelism:
- We can parallelize execution of map operations since they are isolated
- We can reorder folding if the fold function is commutative and associative
- Commutative -> change order of operands: x*y = y*x
- Associative -> change order of operations: (2+3)+4 = 2+(3+4)=9
6
Q
MapReduce - basics
A
- Programming model & runtime system for processing large data-sets
- E.g., Google’s search algorithms (PageRank: 2005 – 200TB indexed)
- Goal: make it easy to use 1000s of CPUs and TBs of data
- Inspiration: Functional programming languages
- Programmer specifies only “what”
-
System determines “how”
- Schedule, parallelism, locality, communication..
-
Ingredients:
- Automatic parallelization and distribution ( # nodes ,
- Fault-tolerance
- I/O scheduling
- Status and monitoring
7
Q
Simplified View of Architecture
A
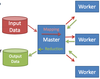
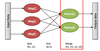
- Input data is distributed to workers (i.e., available nodes)
- Workers perform Data computation
- Master coordinates worker selection & fail-over
- Results stored in output data files
8
Q
MapReduce Programming Model
A
- Input & output: each a set of key/value pairs
- Programmer specifies two functions:
-
map (in_key, in_value) -> list(out_key, intermediate_value)
- Processes input key/ value pair
- Produces set of intermediate pairs
-
reduce (out_key, list(intermediate_value)) -> list(out_value)
- Combines all intermediate values for a particular key
- Produces a set of merged output values (usually just one)
- User also specifies I/O locations and tuning parameters
- Partition (out_key,number of partitions) -> partition for out_key
-
map (in_key, in_value) -> list(out_key, intermediate_value)
9
Q
Map() function
A
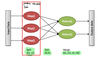
- Records from the data source (lines out of files, rows of a database, etc.) are fed into the map function as key-value pairs: e.g., (filename, line)
- Map() produces one or more intermediate values along with an output key from the input
10
Q
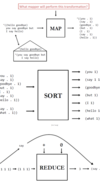
Sort and schuffle
A
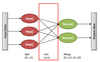
- Map reduce framework
- Shuffles and sorts intermediate pairs based on key
- Assigns resulting streams to reducers
11
Q
Reduce()
A
- After the map phase is over, all the intermediate values for a given output key are combined together into a list
- Reduce() combines those intermediate values into one or more final values for that same output key
- In practice, usually only one final value per key)
12
Q
MapReduce execution stages
A
- Scheduling: assigns workers to map and reduce tasks
- Data distribution: moves processes to data (Map)
- Synchronization: gathers, sorts, and shuffles intermediate data (Reduce)
- Errors and faults: detects worker failures and restarts
13
Q
MapReduce example: Word count
A
- Word count: Count the frequency of word appearances in set of documents
-
MAP: Each map gets a document. Mapper generates key/value pairs each time the word appears (word,”1”)
- INPUT: (filename, fileContent), where FileName is the key and FileContent is the value
- OUTPUT: (word wordApparence), where word is key and wordApparence is value
-
REDUCE: Combines the values per key and computes the sum
- INPUT: (word,List) where word is the key and Listis the value
- OUTPUT: (word, sum) where word is the key and sumis the value
14
Q
Combiners
A
- Often a map task will produce many pairs of the form (k,v1), (k,v2), … for the same key k
- E.g., popular words in Word Count
- Can save network time by pre-aggregating at mapper
- For associative ops. like sum, count, max
- Decreases size of intermediate data
- Example: local counting for word count:
- def combiner(key, values): output(key, sum(values))
15
Q
Partition Function
A
- Inputs to map tasks are created by contiguous splits of input file
- For reduce, we need to ensure that records with the same
- intermediate key end up at the same worker
- System uses a default partition function e.g., hash(key) mod R
- Sometimes useful to override
- Balance the loads
- Specific requirement on which key value pairs should be in the same output files
16
Q
Parallelism
A
- map() functions run in parallel, creating different intermediate values from different input data sets
- reduce() functions also run in parallel, each working on a different output key
- All values are processed independently
- Bottleneck: reduce phase can’t start until map phase is completely finished.

19
Q
MapReducable?
A
- One-iteration algorithms are perfect fits
- Multiple-iteration algorithms are good fits
- But small shared data have to be synchronized across iterations (typically through filesystem)
- Some algorithms are not good for MapReduce framework
- Those algorithms typically require large shared data with a lot of synchronization (many machine learning algorithms)
- Many alternatives: Iterative MapReduce Frameworks or Bulk Synchronous
- Processing Frameworks

21
Q
Iterative MapReduce
A
- Iterative algorithms: Repeat map and reduce jobs
- Examples: PageRank, K-means, SVM and many more
- In MapReduce, the only way to share data across jobs is stable storage -> slow !
- Some proposed solutions include: Twister and Spark

24
Q
BSP model NN
A
- Processor-memory pairs
- Communications network that delivers messages in a point- to-point manner
- Mechanism for the efficient barrier synchronization for all or a subset of the processes
- There are no special combining, replicating, or broadcasting facilities
