Chapter 1 Flashcards
(53 cards)
- What is an independent variable?
A variable thought to be the cause of some effect. The term is usually used in experimental research to denote a variable that the experimenter has manipulated.
- What is the dependent variable?
A variable thought to be affected by changes in an independent variable. You can think of this as an outome.
- What is a predictor variable?
A variable thought to predict an outcome variable. This is basically another term for independent variable - some may not agree..
- What is an outcome variable?
A variable thought to change as a function of changes in a predictor variable. This term could be synonymous with “dependent variable” for the sake of an easy life..
- What is a catergorical variable?
A categorical variable is one that is made up of categories. An example is species (human, domestic cat, bat etc). In it’s simplest form it names just 2 things - such as male or female, dead or alive etc.
- What is a continuous variable?
A continuous variable is one that gives a score for each participant and can take on any value on the measurment scale that is being used.
- What is a binary variable?
A categorical variable that has only 2 possible states - eg male, female
- What is a nominal variable?
Nominal variables can also be known as categorical variables having two or more categories without having any kind of natural order. They are variables with no real numeric value, such as occupation or political party affiliation.
- What is an ordinal variable?
An ordinal variable is a categorical variable for which the possible values are ordered. However, these data tell us nothing about the differences between the values.
- What is an interval variable?
An interval variable is a continuous variable where the difference between two values is meaningful. The difference between a temperature of 100 degrees and 90 degrees is the same difference as between 90 degrees and 80 degrees.
- What is a ratio variable?
Ratio variables are similar to interval variables, but with the added condition that 0 (zero) of the measurement indicates that there is none of that variable.
Reaction time is a good example as the ratio intervals will be the same for any 50ms difference for example..
- What is a discrete variable?
A continuous variable that can only take on certain values - usually whole numbers. Age is a good example where we usually only take the years not nono seconds!
- What is measurment error?
Observational error (or measurement error) is the difference between a measured value of quantity and its true value. In statistics, an error is not a “mistake”.
Variability is an inherent part of things being measured and of the measurement process.
- What is the difference between validity and reliability?
- To ensure measurment error is kept low we can use validity and reliability to check.
- Validity checks if the instrument used measures the variables it is meant to - while reliability checks that the measures are consistent accross different situations.
- What are correlational research methods?
- Correlational or cross-sectional research involves observing a natural occurence without actively interfering with the process.
- This is very different to experimental research where we manipulate a variable to see it’s effect on another.
- What is a confounding variable?
Confounding variables (aka third variables) are variables that the researcher failed to control, or eliminate, damaging the internal validity of an experiment.
- What are the two key types of variation in statistics?
- Systematic variation (due to the experimenter doing something in one condition but not in the other)
- Unsystematic variation (variation results from random factors that exist between the experimental conditions - eg. natural ability ,time of day etc)
- What is a repeated measures design?
Repeated measures design uses the same subjects with every branch of research, including the control.
For instance, repeated measurements are collected in a longitudinal study in which change over time is assessed. Other (non-repeated measures) studies compare the same measure under two or more different conditions.
- What is an independent measures design?
An independent measures design is a type of method used during a psychology experiment that involves two or more separate groups, each containing different individuals, where each participant only takes part in each condition once.
- What effects may be bad for a repeated measures design?
- Practice effects: participants may be too familiar with the second condition due to the experimental condition and/or measures being used (you could get ceiling or floor effects)
- Boredom effects: the second condition may have issues if participants are tired or bored after the first condition
We can counterbalance the order in which a participant gets a condition to minimise these effects..
- Why is randomisation important?
Randomization refers to the practice of using chance methods (random number tables, flipping a coin, etc.) to assign subjects to treatments. Doing so will minimise the risk that groups differ on variables other than the one being maipulated.
- What are the 2 main ways a distribution can deviate from normaility?
- Skew (lack of symetry)
- Kurtosis (pointiness)
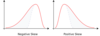
- Draw a diagram showing 3 Kurtosis lines.

- Draw a leptokurtic distribution and a Platykurtic distribution.
An example of a platykurtic distribution is the uniform distribution, which does not produce outliers. Distributions with kurtosis greater than 3 are said to be leptokurtic. An example of a leptokurtic distribution is the Laplace distribution.