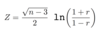Formulas and Definitions Flashcards
(56 cards)
Q1=
0.25 (n+1)th value
OR
(n+1)/4
Q2=
it’s the median
(n+1)/2
Q3=
0.75 (n+1)th value
OR
3(n+1)/4
Ecart entre 2 quartiles =
Interquartile range
Median =
To find the Median, place the numbers in value order and find the middle.
Variance =
𝞼2
Average of squared differences from the mean
Why using samples?
We rarely can collect data on ALL members of a population because of Time and Cost, but we still need to be able to make conclusions about the entire population.
So we use samples
Samples guidelines and bias:
-
All elements in the sample must be part of the population as it’s defined
- Bias: people under/over the age boundary
-
The sample should be representative of the population
- Bias: collecting data on height and half of the sample plays in the NBA
-
Samples should be independent from each others
- Bias: “Refer a friend” to the study as friends often have a lot of similarities
-
Samples are chosen randomly in many cases
- Bias: Only choosing people from a particular background/ethnicity when the study is about a multicultural country
Sample results are ALWAYS an approximation
Measure of Skewness

Standard deviation =
Square root of variance
𝞼
When should we prefer the mean or the median ?
The mean is mostly preferred because it uses all the data values
However, in case of extreme values, the median might be more representative
Measures of spread VS measures of location
- Sample mean and median are measures of location. They give you a ‘typical’ value of an observation.
- Sample variance and inter-quartile range are measures of spread. They tell you how far observations tend to be from the ‘typical’ value.
- The largest and smallest values give the range of the data, but this is not usually a robust measure of the range of values in the population (as it can vary alot among independent samples).
- The set of five values (x(1), Q1, Q2, Q3, x(n)) is called the five point summary.
Bar chart
VS
Histogram
VS
Box-and-whisker plot
Bar chart: For discrete data. Vertical bars are separate; height is proportional to frequency.
Histogram: For continuous data. Vertical bars are adjacent; if interval widths are different, the area of the rectangle is proportional to frequency.
Box-and-whisker plot: Produced with median, quartiles, max and min. The box extends from one quartile to the other, with the median marked in between.

Symmetry:
Sometimes it is important to judge whether a dataset is symmetric. Look at :
- Whether mean and median are close
- Whether median is about midway between the quartiles
- Whether the histogram is symmetric
Different statistical models:
- Yes/No survey (binomial)
- Number of computer server crashes at City University per week (Poisson)
- Returns on shares (normal)
Standard Normal curve
A commonly used distribution for continuous variables is the Normal distribution illustrated below. It is symmetric. Parameters are μ, the mean, and σ the standard deviation.
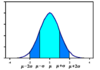
The curve in the image has a sdev of 1
Normal tables:
Z is said to have a standard normal distribution.
To calculate probabilities associated with Normal variables, use tables or computers. Normal tables usually give Φ(z) = P(Z ≤ z) only for positive numbers z. Equivalent values for negative numbers z can be found by symmetry:
Characteristics of a Binomial Experiment:
- The process consists of a sequence of n trials
- Only two exclusive outcomes: success or failure
- Probability of success = p
- Probability of failure = 1-p
- Trials and outcomes are independent
Binomial notations
X∼Binom(n,p)
Binomial success probability formula
n=total population
j= success
p= probability

Binomial coefficient calculation formula:
(x! on calculator)
Use nCr in calculator

Normal approximation to Binomial:
When n is large, Binomial(n, p) gives roughly the same results as N (np, np(1 − p))
Continuity correction: for X Binomial and Y Normal:
- P(X > 10) = P(X ≥ 11), but
- P(Y > 10) ≠ P(Y ≥ 11),
so we use P (Y \> 10.5) as a suitable approximation. Similarly P(X \< 10) = P(X ≤ 9) so use P(Y \< 9.5) as an approximation.
Random variable, Distribution and Observations:
- A random variable is a numerical quantity whose value is to be determined by an experiment, but the experiment has not yet been performed.
Examples are: score on a die, height of a random student.
- A distribution describes the values that might be observed and how likely they are. Many quantities can be assumed to have standard distributions, like Normal, Binomial.
- After the experiment the value is known: this is an observation.
We use X, Y, Z to denote random variables, x, y, z to denote observations.