ANOVA and Regression Flashcards
(116 cards)
Define the terms scatter plot, correlation, and regression line.
Scatter plot- a 2-dimensional graph of data values.
Correlation- A statistic that measures the strength and direction of a linear relationship between two quantitative variables
Regression line- an equation that describes the average relationship between a quantitative response variable and an explanatory variable
What is Pearson’s sample correlation coefficient (r), what are its bounds, and how is it calculated?

What are typical questions to ask from a scatter plot
- What is the average pattern? Does the scatter plot look like a straight line or curved? 2. What is the direction of the pattern? Negative/ Positive association? 3. How much do individual points vary from the average pattern? 4. Are there any unusual data points?
What is the meaning if r= 1,0,-1?
All points fall on a straight positive line, the best straight line through the data is exactly horizontal, and all points fall on a straight negative line.
Equation for a straight regression line

Three general types of regression?
Simple linear regression, ploynomial regression, multiple linear regression
Assumptions for error term in simple linear model
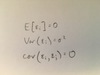
What are some topics of interest in regression?
- Is there a linear relationship? 2. How to describe the relationship 3. How to predict new value 4. How to predict the value of explanatory variable that causes a specified response
What is the E[Yi] for a simple linear regression model

Definitions of B1 and B0
B1- the slope of the regression line which indicates the change in the mean of the probability distribution of Y per unit increase in X B0- the intercept of the regression line. If 0 is in the domain of X then B0 gives the mean of the probability distribution of Y at X=0
Are Y, X, B, eps random/fixed and known/unknown?
Y- Random, known X- Fixed, known B- Fixed, unknown eps- Random, unknown
Describe the process of least squares estimation

Equation for a residual

Sxx, Syy, Sxy

Gauss-Markov Theorem
Under certain assumptions (mean zero, independent, homoskedastic errors) the least squares estimators are the minimum variance unbiased estimators among all linear estimators
Best equations for B0 and B1 using least squares estimation

For simple linear regression, equation for SSE, degrees of freedom, relation to sig^2

Maximum likelihood estimation, explain what changes with regression from LSE.
MLE assumes normality. B estimators are the same but estimators for sig^2 differ. We get SSE/n for MLE which is biased, but asymptotically unbiased. Normal assumption necessary for testing and interval construction
J and n in terms of 1 vectors
J- 11’ n-1’1
H matrix
X(X’X)^-1 X’
Linear form of y
By
Quadratic form of y
y’Ay
Quadratic forms are common in linear models as a way of _____ The sum of squares can be decomposed in terms of _______ A quadratic form of normal Y is _______ Independence of quadratic forms is based on _________
expressing variation quadratic forms Chi-squared distribution idempotent matrices
If l1=B1y and l2=B2y then what is cov(l1,l2)
cov(l1,l2)=B1cov(y)B2’




























































