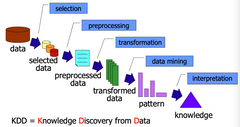
Knowledge Discovery Process
Analysis techniques, methods
Descriptive methods:
Extract interpretable models describing data, for example client segmentation.
Predictive methods:
Exploidt some known variables to predict unknown or future values of variables, for example spam emails.
Attributes types
Nominal: ID, eye color, zip codes
Ordinal: Rankings, grades, size in {tall, medium, short}
Interval: calendar dates, temperatures in celsius
Ratio: temperature in Kelvin, length, time, counts
Nominal attributes possesses
Distinctness
Ordinal attribute possesses
distinctness, order
Interval attribute
Distinctness, order, addition
Ratio attribute
Distinctness, order, addition, multiplication
Data quality problems
Noise, outliers, missing values, duplicate data
Important characteristics of structured data
Dimensionality: curse of dimensionality
Sparsity: Only presence counts
Resolution: Patterns depend on the scale
Aggregation
Combining attributes into single one.
Purpose:
Data reduction: reducing attribute number ( sampling, feature selection, discretization)
Change of scale: from regions into states
Stability: aggregated data tends to be more stable (less deviation)
Sampling
Samping is necessary because employing the entire data set is too expensive.
Sampling works if the sample set is representative of the entire dataset.
A sample is representative if it has approximately the same property as the original set of data.
Types:
Simple Random: Randomly selected
Without replacement: An object can be taken only once
With replacement: Same object can be takes more than once.
Stratified: Split data into several partitions, take random samples from each partition
Dimensionality reduction
When dimensionality increases, data becomes more sparse in the space it occupies; Definition of distance and density between points become less meaningful. To prevent this we have dim. reduction:
Principal comp. analysis: find projection that captures largest amount of variation in data.
Singular value decomp.
Feature subset selection: remove redundant features and irrelevant features
Feature subset selection techniques
Bruteforce: try all possible subsets as input of data mining algo
Emebedded: features are selected naturally by the data mining algo
Filter: features selected before algorithm is run
Wrapper: use algorithms as black box to get best subset
Feature Creation
Create new attribute that represent better the inormation in the data set.
Feature Extraction: domain specific
Mapping Data to new space: for example Fourier Transform
Feature Construction: combine features
Discretization
Split attribute domain from continuos into discrete.
Reduces cardinality of attribute domain.
Techniques:
- N intervals with same width (Incremental, easy to do, can be badly affected by outliers and sparse data)
- N intervals approx same cardinality (non incremental approach, good for sparse data and outliers)
- Clustering (fits wel sparse data)
Attribute transformation
Function that maps attribute values to a new set of values;
Example: Normalization ( min-max, z-score, decimal scaling)
Similarity/Dissimilarity for simple attributes

Minkowski distance
r=1: city block (hamming distance)
r = 2: euclidean distance
r -> ∞: maximum distance between any component of the vectors.
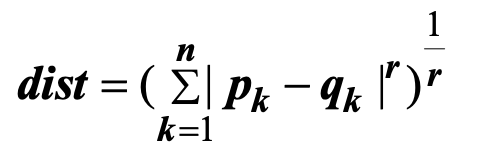
Properties of metrics

Common properties of similarities
s(p,q) = 1 only if p = q
s(p, q) = s(q, p) for all p and q.
Similarity between binary vectors
Simple matching:
SMC = matches/(number of attributes)
Jaccoard Coefficients:
J = (11 matches) / (number not both zero attribute values) = (M11) / (M01 + M10 + M11)
Cosine similarity

Combining similarities and combining weighted similarities

Goal of association rules
Expoloratory technique.
Extraction of frequent correlations or pattern form a transactional database
Example:
diapers => beer
- 2% of transactions contains both items
- 30% of the ones containing diapers contais also beer




