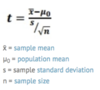statistics notes 2020 march 30 Flashcards
(258 cards)
Data types
Categorical and numerical
types of Categorical data
Nominal, Ordinal
Nominal:
Named data which can be separated into discrete categories which do not overlap.
Ordinal:
the variables have natural, ordered categories and the distances between the categories is not known.
types of numerical data
Discrete, continuous
Ordinal data
a categorical, statistical data type
the variables have natural, ordered categories and the distances between the categories is not known.
data which is placed into order or scale (no standardised value for the difference)
(easy to remember because ordinal sounds like order).
e.g.: rating happiness on a scale of 1-10. (no standardised value for the difference from one score to the next)
Nominal Data mytutor.co.uk
Named data which can be
separated into discrete categories which do not overlap.
(e.g. gender; male and female) (eye colour and hair colour)
An easy way to remember this type of data is that nominal sounds like named,
nominal = named.
Ordinal Data
mytutor.co.uk
Ordinal data:
placed into some kind of order or scale. (ordinal sounds like order).
e.g.:
rating happiness on a scale of 1-10. (In scale data there is no standardised value for the difference from one score to the next)
positions in a race (1st, 2nd, 3rd etc). (the runners are placed in order of who completed the race in the fastest time to the slowest time, but no standardised difference in time between the scores).
Intervaldata:
comes in the form of a numerical value where the differencebetween points is standardisedand meaningful.
Interval Data
mytutor.co.uk
Interval data:
comes in the form of a numerical value where the difference between points is standardised and meaningful.
e.g.: temperature, the difference in temperature between 10-20 degrees is the same as the difference in temperature between 20-30 degrees.
can be negative
(ratio data can NOT)
Ratio Data
mytutor.co.uk
Ratio data:
much like interval data – numerical values where the difference between points is standardised and meaningful.
it must have a true zero >> not possible to have negative values in ratio data.
e.g.: height be that centimetres, metres, inches or feet. It is not possible to have a negative height.
(comparing this to temperature (possible for the temperature to be -10 degrees, but nothing can be – 10 inches tall)
inferential statistics
Population: an entire group of items, such as people, animals, transactions, or purchases >> Descriptive statistics applied if all values in the dataset are known.
>> not possible or feasible to analyse >>
Sample: a selected subset, called a sample, is extracted from the population.
The selection of the sample data from the population is random >> Inferential statistics applied >> develop models to extrapolate from the sample data to draw inferences about the entire population (while accounting for the influence of randomness)
Quantitative analysis can be split into two major branches of statistics:
Descriptive statistics (if all values in the dataset are known)
Inferential statistics (extrapolates from the sample data to draw inferences about the entire population)
inferential
következtetési, deductive
Descriptive statistical analysis
As a critical distinction from inferential statistics, descriptive statistical analysis applies to scenarios where all values in the dataset are known.
Confidence, confidence level
Confidence is a measure to express how closely the sample results match the true value of the population.
Confidence level: 0% - 100%
95%: if we repeat the experiment numerous times (under the same conditions), the results will match that of the full population in 95% of all possible cases.
Hypothesis Testing
Hypothesis test:
evaluate two mutually exclusive statements to determine which statement is correct given the data presented.
incomplete dataset >> hypothesis testing is applied in inferential statistics to determine if there’s reasonable evidence from the sample data to infer that a particular condition holds true of the population.
null hypothesis
A hypothesis that the researcher attempts or wishes to “nullify.”
most of the world believed swans were white, and black swans didn’t exist inside the confines of mother nature. The null hypothesis that swans are white
The term “null” does not mean “invalid” or associated with the value zero.
In hypothesis testing, the null hypothesis (H0)
In hypothesis testing, the null hypothesis (H0) is assumed to be the commonly accepted fact but that is simultaneously open to contrary arguments.
If substantial evidence to the contrary >> the null hypothesis is disproved or rejected >> the alternative hypothesis is accepted to explain a given phenomenon.
The alternative hypothesis
The alternative hypothesis is expressed as Ha or H1.
Covers all possible outcomes excluding the null hypothesis.
What is the relationship between the null hypothesis and alternative hypothesis?
null hypothesis and alternative hypothesis are mutually exclusive,
which means no result should satisfy both hypotheses.
a hypothesis statement must be
a hypothesis statement must be clear and simple. Hypotheses are also most effective when based on existing knowledge, intuition, or prior research.
Hypothesis statements are seldom chosen at random. a good hypothesis statement should be testable through an experiment, controlled test or observation.
(Designing an effective hypothesis test that reliably assesses your assumptions is complicated and even when implemented correctly can lead to unintended consequences.)
A clear hypothesis
A clear hypothesis tests only one relationship and avoids conjunctions such as “and,” “nor” and “or.”
A good hypothesis should include an “if” and “then” statement
(such as: If [I study statistics] then [my employment opportunities increase])
The good hypothesis sentence structure
The first half of this sentence structure generally contains an independent variable (this is the hypothesys) (i.e., if study statistics) in the
second half: a dependent variable (whatyou’re attempting to predict) (i.e., employment opportunities).
A dependent variable represents
A dependent variable represents what you’re attempting to predict,
2nd half of the hypothesys sentence
The independent variable is
The independent variable (in the first half of the sentence) is the variable, that supposedly impacts the outcome of the dependent variable (which is the 2nd half of the hypothesys senetence)
double-blind
where both the participants and the experimental team aren’t aware of who is allocated to the experimental group and the control group respectively.