String Strategies Flashcards
(7 cards)
Reverse Words in a Sentence
Reverse the order of words in a given sentence(an array of characters). Here are a few examples:
“Hello World” -> “World Hello”
“The quick brown fox jumped over the lazy dog.” -> “dog. lazy the over jumped fox brown quick The”
Runtime Complexity: Linear, O(n). Position of all the elements in the sentence is changed.
Memory Complexity: Constant, O(1).
The solution reverses every word in-place i.e. it does not require any extra space.
Here is how the solution works.
- Reverse the string.
- Traverse the string and reverse each word in place.
Let’s apply this solution to our example: “The quick brown fox jumped over the lazy dog.”.
- Reverse the string “.god yzal eht revo depmuj xof nworb kciuq ehT”
- Reverse each word in-place “dog. lazy the over jumped fox brown quick The”

Remove Duplicates
Given a string that contains duplicate occurrences of characters, remove the duplicate occurrences.
For example, if the input string is “abbabcddbabcdeedebc”, after removing duplicates it should become “abcde”.
Runtime Complexity: Linear O(n).
Memory Complexity: Linear, O(n).
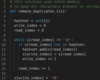
In this solution, we’ll keep two pointers, or indices one for current reading position and one for the current writing position. Whenever we encounter the first occurrence of a character, we add it to the HashSet. Any character already existing in the HashSet is skipped on any subsequent occurrence. Below is an overview of the algorithm.
read_pos = 0
write_pos = 0
for each character ‘c’ in str
if ‘c’ not found in hashset
add ‘c’ to hashset
str[write_pos] = str[read_pos]
write_pos++
read_pos++
Let’s go through this step-by-step.
Remove White Spaces
Given a null terminated string, remove any white spaces (tabs or spaces). For example:
All greek to me.
After removing the white spaces, the string should look like this:
Allgreektome.
Runtime Complexity: Linear, O(n).
Memory Complexity: Constant, O(1).
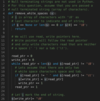
This problem can be solved with two pointers. Here is an overview.
read_ptr and write_ptr initialized to start of string, str[0]
With the read_ptr, iterate over the input string reading one character at a time.
While moving read_ptr towards the end of the array:
if read_ptr points to a white space, skip
if read_ptr points to any other character, write that to write_ptr and increment the write_ptr.
Terminate the loop when the read_ptr reaches the end of the string.
At this point, the write_ptr will point to the string with all white spaces removed.
String Segmentation

We are given a dictionary of words and a large input string. We have to find out whether the input string can be completely segmented into the words of a given dictionary.
Polynomial, O(n2) runtime. Memory Complexity is O(n2), because we create a substring on each recursion call. Creating a substring can be avoided if we pass indices.
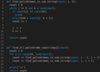
We can solve this problem by segmenting the large string at each possible position to see if the string can be completely segmented to words in the dictionary. If we write the algorithm in steps it will be as follows:
n = length of input string
for i = 0 to n-1
firstword = substring (input string from index [0 , i] )
secondword = substring (input string from index [i+1 , n-1] )
if dictionary has firstword
if secondword is in dictionary OR second word is of zero length, then return true
recursively call this method with secondword as input and return true if it can be segmented

Find all Palindrome Substrings

Given a string find all non-single letter substrings that are palindromes.
Runtime Complexity: Polynomial, O(n2).
Memory Complexity: Constant, O(1). We can reduce the runtime of this algorithm to O(n2) by using the following approach.
For each letter in the input string, start expanding to the left and right while checking for even and odd length palindromes. Move to the next letter if we know a palindrome doesn’t exist.
We expand one character to the left and right and compare them. If both of them are equal, we print out the palindrome substring.
Regular Expression

Given a text and a pattern, determine if the pattern matches with the text completely or not at all by using regular expression matching. For simplicity, assume that the pattern may contain only two operators: ‘.’ and ‘*’. Operator ‘*’ in the pattern means that the character preceding ‘*’ may not appear or may appear any number of times in the text. Operator ‘.’ matches with any character in the text exactly once.
Exponential Runtime, Exponential Memory
We’ll compare the text and pattern character by character and recursively compare the remaining text and remaining pattern. The only difference is that in the first solution, we create sub-strings for the remaining text and the remaining pattern on each recursive call, which is unnecessary. In this solution, we use indices of text and pattern instead of creating sub-strings and pass the same strings in the recursive calls.
The worst case time complexity for this solution is still exponential but we do save memory and time that was previously being spent on copying strings. For example, if text is’aaa’ and pattern is ‘a*a*a*’. First, we’ll match a*a* with aaa, aa, a, and an empty string. Then we’ll match a* with aaa, aa, a, and an empty string.

Word Cloud Data
You want to build a word cloud, an infographic where the size of a word corresponds to how often it appears in the body of text.
To do this, you’ll need data. Write code that takes a long string and builds its word cloud data in a dictionary, where the keys are words and the values are the number of times the words occurred.
Think about capitalized words. For example, look at these sentences:
'After beating the eggs, Dana read the next step:'
'Add milk and eggs, then add flour and sugar.'
What do we want to do with “After”, “Dana”, and “add”? In this example, your final dictionary should include one “Add” or “add” with a value of 2. Make reasonable (not necessarily perfect) decisions about cases like “After” and “Dana”.
Assume the input will only contain words and standard punctuation.
In our solution, we make three decisions:
- We use a class. This allows us to tie our methods together, calling them on instances of our class instead of passing references.
- To handle duplicate words with different cases, we choose to make a word uppercase in our
dictionaryonly if it is always uppercase in the original string. While this is a reasonable approach, it is imperfect (consider proper nouns that are also lowercase words, like “Bill” and “bill”). -
We build our own
split_words()method instead of using a built-in one. This allows us to pass each word to ouradd_word_to_dictionary()method as it was split, and to split words and eliminate punctuation in one iteration.
To split the words in the input string and populate a dictionary of the unique words to the number of times they occurred, we:
- Split words by spaces, em dashes, and ellipses—making sure to include hyphens surrounded by characters. We also include all apostrophes (which will handle contractions nicely but will break possessives into separate words).
- Populate the words in our dictionary as they are identified, checking if the word is already in our dictionary in its current case or another case.
If the input word is uppercase and there’s a lowercase version in the dictionary, we increment the lowercase version’s count. If the input word is lowercase and there’s an uppercase version in the dictionary, we “demote” the uppercase version by adding the lowercase version and giving it the uppercase version’s count.
Runtime and memory cost are both O(n)

