SWE Flashcards
(143 cards)
SWE: What does it mean for function f(n) to be big-O of g(n), or f(n) in O(g(n)), or f(n) = O(g(n))
There exists number n* and constant c so for all n > n*,
f(n) < cg(n)
SWE: At a high level, what does it mean for f(x) to be big-Omega of g(x)?
It means g(x) is big-O of f(x); it reverses the relationship.
What type of bound does big-O provide on the runtime of our algorithm? What about big-Omega? What about big-Theta?
Big-O provides an upper bound
Big-Omega provides a lower bound
Big-Theta provides both an upper and lower bound, or a tight bound
SWE: What does it mean for f(n) to be big-Theta of g(n)
f(n) is both big-O of g(n) and big-Omega of g(n)
SWE: When we use big-O, are we typically describing best-case, worst-case, or expected-case run time?
Worst case. (But it can be used for the other two.)
SWE: What does asymptotic analysis do for function f(n)? What is our primary tool for asymptotic analysis?
It describes the limiting behavior for function f(n). We use big-O.
SWE: If we have two arrays with lengths a and b respectively, what is big-O run time for nested loops iterating through all elements of one array for all elements of another?
O(ab)
SWE: What are the two main rules for calculating big-O of a function f(n)?
Drop any constants, either multiplicative or additive, and drop any additive terms that are asymptotically not the largest.
SWE: What is big-O of f(n) = 4*2n + 3n10 + 10?
O(2n)
SWE: What “general pattern” emerges for O(log n) runtimes?
Continually dividing n by some constant, such as 2, until you reach 1. (Or, continually multiplying a constant by another constant until you reach n.)
SWE: Why can string questions be approached as array questions, and vice versa?
Because a string is just an array of characters.
SWE: What is a (singly) linked list?
A list of nodes, where each node has a value and a pointer to the next node.
SWE: What is a double linked list?
A list of nodes, where each node has a value and a pointer to both the previous and next node.
SWE: What is an advantage of linked lists over traditional arrays? What is a disadvantage?
Advantage: You can add and remove elements from the end of the list in constant time (whereas with a resizable array, additions are only amortized constant time)
Disadvantage: You can no longer use an index to find a value in constant time. If you want the kth element, you must iterate through k nodes.
SWE: In a linked list, what is a null node, and what is is used for? (In 122’s particular implementation, which I’ll use)
It is a note with a null data value and a null pointer to the next node. It serves as the end of the linked list, or the final node. When iterate throught he list and find a null node, we know the list is over.
SWE: In a linked list, what is a root node?
The root node is the current first node.
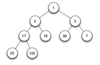
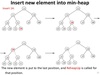
SWE: How would we draw a 2 element linked list, where we have 3 nodes: a root node, a normal node, and our null node?

SWE: When we add a node to a linked list, and the linked list is drawn in our typical way, do we add the node to the left or the right? Why?
The left!
SWE: How do we add a new node to a linked list?
Set the new node to be the root node, and set the pointer of the new node to go to the old root node.
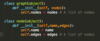
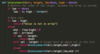
SWE: How do you implement a linked list in python, with add and remove methods?

SWE: Are linked list problems commonly recursive or iterative?
Recursive, because linked lists have a naturally recursive structure. (But there are many problems with iterative solutions too!)
SWE: What is the runner technique for linked lists?
You examine the linked list using two pointers: one that is “slow”, and one that is “fast” and is generally at a farther position in the linked list, and which moves faster than the other.
This is a pretty general technique, but be aware that it exists: examining with two pointers might be handy for many problems.
SWE: What is a hash table used for, and what makes it so useful?
A hash table is a data structure that maps keys to values; you insert key-value pairs, and then search for a key to get its value.
It is useful because it enables fast lookup of elements, in basically constant time as long as your hash table has enough available memory.