11 - Strings and Text 2 Flashcards
(19 cards)
How can a suffix tree for a string S be derived from a suffix trie?
- collapse each path consisting of unary branch nodes into a single edge
- label each new edge with concatentation of labels from the corresponding trie edges

Suffix tree of a string S
- construct S* from S by appending a character ($) that doesn’t appear in S
- suffix tree of S* (loosely, of S) is a rooted tree in which
- each edge labelled by a string (its edge label)
- all branch nodes have >= 2 children
- no 2 children of a node have edge labels beginning with same character
- 1-to-1 corrsespondence between suffixes of S* and leaf nodes v, in sense that the path label of v is precisely that suffix
- the path label of a node is concatenation of edge labels on path from root to that node
What are the properties of a suffix tree?
- Number of leaf nodes is n+1 (n = |S|)
- number of branch nodes is <= n
- total number of nodes is O(n)
- sum of lengths of edge labels is same as suffix trie
- no better than O(n2)
How to avoid space overhead in suffix tree?
- Use short edge labels
- replace a string X by pair of integers (i, j) such that
- X = S*(i .. j)
- each short edge label has length O(1)
- so sum of lengths of edge labels is O(n)
- replace a string X by pair of integers (i, j) such that
Example
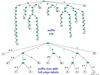
Example
suffix tree with full edge labels vs short edge labels
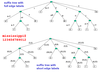
What is naive method for constructing a suffix tree
- Let S be string of length n. Append a character to form S*
- Creating suffix tree T:
- 1) create suffix trie for S*
- SuffTrie suffTrie = new SuffTrie();
- for (int j=1; j <= n+1; j++)
- insert(suffTrie, s[j … n+1);
- 2) amalgamate edges of paths containing unary branch nodes into single edges
- 3) create short edge labels
- 1) create suffix trie for S*
- Worst case complexity
- 1) O(n2)
- 2) O(n2)
- 3) O(n2)
- Overall: O(n2)
- Space complexity O(n2)
*
What is the better method for constructing a suffix tree T?
- Create suffix tree (with short labels) for S* directly:
- SuffTree suffTree = new SuffTree();
- for (int j=1; j<=n+1; j++)
- insert(suffTree, s[j .. n+1]);
- To insert a suffix, follow an existing path and split from a certain point
- Worst case time complexity still O(n2)
- But space complexity O(n)
- Average time complexity O(n log n)
Example
comes after better method for constructing suffix tree

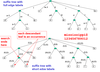
Searching a text T of length n, for a string S of length m in a suffix tree?
- build suffix tree for T
- O(n) time
- follow a path from root matching characters
- O(m) time
- all occurrences are represented by leaf node descendants from point where search ends
- can search text of length n for k short strings of total r in O(n + r) time
- e.g. find all occurences of is in mississippi
Example of finding occurences in suffix tree
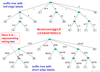
Finding longest repeated substring in text T, length n
- build suffix tree for T
- O(n) time
- traverse the tree
- a longest repeat is represented by a branch node having greatest string depth
- string depth of a node is sum of lengths of the edge labels on the path from root to that node
- i.e. it is length of the path label of that node
- traversal is also O(n) is overall O(n)
Example of finding longest repeated substring in suffix tree
Finding longest common substring (LCSt) of strings S1, S2 of lengths m, n in suffix tree
- e.g. S1 = dadbcdb and S2 = abcdacda
- build generalised suffix tree T for S1 and S2
- this is the suffix tree for S = S1 # S2
- i.e. $ is the concatentation of S1, #, S2, $ in that order (where # nor $ occurs in S1 or S2)
- traverse tree
- longest common substring is represented by a common branch node with greatest string depth
- a branch node is common if it has 2 descendant leaf nodes representing positions starting in S1 and S2
Example of finding longest common substring 1/2

Example of finding longest common substring 2/2

Identifying common branch nodes
* maintain booleans at each node v of T as follows:
* define b<sub>i</sub>(v) as true if and only if
* path label of a descendant leaf node of v starts in string S<sub>i</sub> ∈ (i {1, 2})
* a branch node v of T is common if and only if b<sub>1</sub>(v) ∧ b<sub>2</sub>(v)
- computing the bi values
- let v be a leaf node corresponding to suffix no. j of S, so path label of v is S(j .. m+n+2)
- b1(v) = true if and only if 1 <= j <= m
- b2(v) = true if and only if m+2 <= j <= m+n+1
- for a branch node v, bi(v) = bi(w1) ∨ bi(w2) ∨ … ∨ bi(wr)
- where w1, …, wr are the children of v (i {1,2})
Overall of finding longest common substring problem (LCSt)
- Given strings S1, S2 of lengths m, n
- build generalised suffix tree T
- O(m+n) time
- calculate bi(v) values
- O(m+n) time using a traversal of T
- output path label of a common branch node w of T with max string depth
- O(m+n) time
- in practise, w may be computed during travesal in 2
- overall O(m+n) time and space
Example of finding longest common substring with questions

