L7 - (PL) Multinomial and Ordered Choice Models Flashcards
What is the likelihood estimation function for a binomial distribution?
- More generally
- n –> total number of events
- h –> no. of times the desired outcome was observed
- p –> is the probability of occurrence in one singular event
- MLE is ignorant of any data collected on the phenomenon
- MLE doesn’t work on intuition but estimating a parameter based on the data given (so may not have p = 0.5 based on our sample data )
- Based on our example of 1000 coin tosses, the probability of heads (p) that maximises the LL function is actually 0.58 –> which is different from our intuition
- MLE doesn’t work on intuition but estimating a parameter based on the data given (so may not have p = 0.5 based on our sample data )
- MLE is an iterative procedure to find a single value of p that maximise the likelihood function –> the more information we have the closer we can get to the true parameter

Why has MLE become so popular as a model estimator?
- it’s good for solving more complex models
- e.g. the simultaneous estimation of multiple parameters
- it is also very robust and is good at dealing with complex data
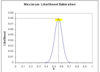
How can we represent the MLE process on a graph?
- MLE can be thought of as mathematically a search along the LL function line for a point that the slope is = 0
- f’(x) = 0
- this is easy to do for simple functions but more complex functions lead to a number of problems in locating this point
- For these complex function, we use the log-likelihood function
What is the mathematical expression of the log-likelihood function?
- It is the product of the probability across different samples that analysts may take for the population of decision-makers
- theta is the parameter to be estimated
- The issue with the multiply probability is that they can be quite small and thus we can end up with a tiny number and the software may find it difficult to identify what that number is
- Hence we log the equation, making it a summation that aids the software in finding the maximum likelihood

How do we test how well a model fits our data?
- Where LLbase is the likelihood function computed without and parameter and using a constant instead, where as LLmodel is the function computed using the data to get an estimation of the parameters

What are the Limitations of the Logit Model?
- “Taste” Variation –> e.g. size of the car matters more to say a large family over that of a bachelor, Low-income households are probably more concerned about the purchase price of a good, relative to its other characteristics, than higher-income households.
- Substitution Patterns
- Property of Independence from Irrelevant Alternatives (IIA) - the ratio of the choice probabilities of any pair of alternatives is independent of the presence or absence of any other alternative in a choice set.
How does the Nested Logit (NL) Model build on the basic version?
Properties of the Nest Logit (NL) Model
- Extreme value distribution of the unobserved proportion of utility; –> still a similar distribution to the original model
- Partially relaxes the IIA assumption in order to accommodate
- different degrees of substitution across alternatives,
- different variances across the alternatives,
- correlation among sub-sets of alternatives.
- This means the NL model groups alternatives into non-overlapping nests and allows different substitution patterns across different alternatives, allows different variances of the error term within each nest, allows correlation among set of alternatives within the nest
- correlation among sub-sets of alternatives.
•Has a closed-form expression for the likelihood function;
How do the probabilities change when one alternative is removed in the NL model?
- The IIA assumption of the original Logit model states that the probability of any pairs of alternatives is independent of whether you add or subtract any alternatives from the choice set
- But looking at the data below this isn’t the case –> with Auto Alone removed individuals need to switch their choices hence we see are doubling in the probability the a decision-maker will pick car pooling
- One thing to note is that once one alternative is removed we see that two of the options see an equal rise in their probability of being chosen –> can we see any similarities between these two options?
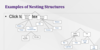
- looking at substitution patterns across alternatives (ways in which we can group (nest) them together due to similar characteristics )
- We can then represent these nests in a tree diagram for Mode Choice
- This allows for different substitution patterns across the next and relax the IIA pattern and allowing for correlation between the error terms of alternatives within the same nest

Examples of Nesting Structures?
Under the NL model, what is the CDF of the error terms?
- The variance looks very similar to the variance of the error term in the multinomial model (with the introduction of λ 2)

How can we derive the Choice Probability of the NL model?
- Marginal probability ==> probability that nest k is chosen
- conditional probability ==> probability that the individual choice alternative i, conditional on the choice of the nest Bk
By substituting both into the CDF function of the error term the probability collapses into the final function

to keep the NL model consistent with Utility maximisation what restrictions are imposed on λk?
- If it’s with the unit interval it applies to all xni but if it is greater than 1 it only applies to SOME of them
- So when you estimate this model this is something you need to check out
