what is statistical inference?
Making decisions in the face of uncertainty. making decisions on the basis that the result achieved was not due to chance or random process
Hypothesis testing is a structure for making these decisions
What are two types of hypothesis?
The null hypothesis and alternative hypothesis
distinguish between type 1 and type 2 error when might they occur?
Type 1 error: rejecting null hypothesis despite it being true. probability of type 1 error occuring is level of significant α
Type 2 error: retain null hypothesis when it is false/ probability of type 2 error occuring is β
these errors might occur during the process of hypothesis testing
what does hypothesis testing consist of?
statement of null hypothesis and selecting significance level. then acquiring data through calculation
statistical calculations tell us whether to reject null hypothesis or not
how is alpha related to type 1 error?
value of alpha, which is related to the level of significance that we selected has a direct bearing on type I errors. Alpha is the maximum probability that we have a type I error. For a 95% confidence level, the value of alpha is 0.05. This means that there is a 5% probability that we will reject a true null hypothesis. In the long run, one out of every twenty hypothesis tests that we perform at this level will result in a type I error.
Reduce alpha to reduce chance of type 1 error
what happens when we decrease probability of an error from occuring?
e probability for the other type increases. We could decrease the value of alpha from 0.05 to 0.01, corresponding to a 99% level of confidence. However, if everything else remains the same, then the probability of a type II error will nearly always increase.
what does the alpha level suggest?
95% Certainty of making the right decision”
what is the conventional alpha level?
Convention: set level of type 1 error (α) to 5% (i.e. 5% chance we reject H0 when it is true), ignore type 2 error (β).
when we start a hypothesis, what do we first assume?
assuming null is true. Then, gather data, and if we are faced with enough evidence, we will switch from null to alternative hypothesis.
features of null and alternative hypothesis
Null hypothesis:
Always about a population value (greek letter)
Always has an “=“
Alternative hypothesis:
Always about a population value (greek letter)
Has one of <, > or ≠
Looks like null, but “=“ has been replaced.
A store manager is considering a new billing system for credit customers. New system will only be cost effective if mean monthly account is more than $170. Random sample of 400 monthly accounts gives sample average of $178. Manager knows that accounts are approximately normally distributed, with standard deviation of $65.
Can the manager conclude from this data that the new system will be cost effective?
Want to find out if µ, true mean monthly account, is bigger than $170.
Null hypothesis
H0:µ=170
Alternative hypothesis
HA:µ>170
what does central limit theorem suggest in regards to hypothesis testing?
Says that sample average has a normal distribution, centre at µ, standard deviation of σ/√n.So, if we calculate ( X̄ - µ)/ ( σ / √n) it should follow a standard normal distribution.
in hypothesis testing, what is a test statistic?
We calculate a test statistic – this measures (in standardised units) how far from the hypothesised µ our sample average is
Z should follow a standard normal distribution IF the true µ is equal to the one in our null hypothesis.
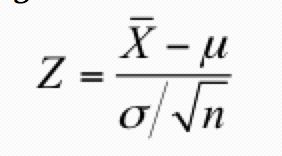
list the two methods in the decision rule
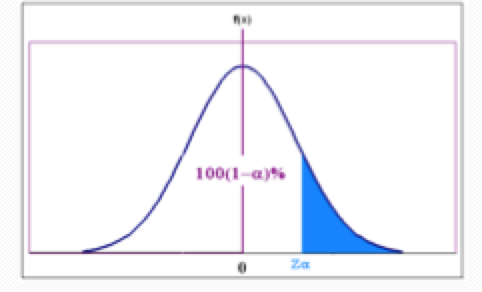
Rejection region
p-value
Decision rule
-rejection region
Say we want to be 95% certain. This means a 5% chance of rejecting H0 when it is true.
So, we find the EXTREME 5% of the standard normal (according to our alternative hypothesis) and this will be our rejection region
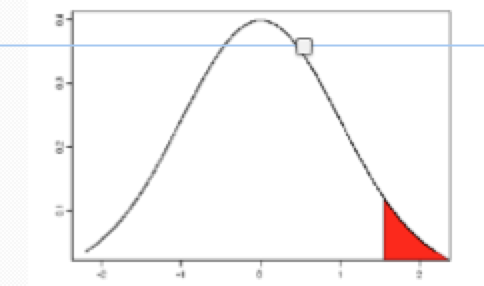
if test statistic is 2.46, describe what to do
Point that marks off top 5% of a standard normal is 1.645.
So, we will reject the null hypothesis if our test statistics lies above 1.645.
Here, Test statistic = 2.46.
Reject the null hypothesis. There is sufficient evidence to conclude that the mean monthly bill is higher than $170.
4 steps for hypothesis test
- Null and alternative hypotheses
- Test statistic
- Decision Rule: Rejection Region or p-value – found from appropriate distribution (std normal)
- Conclusion
Decision rule
describe the p-value
This is probability of getting our test statistic equal or more extreme than the sample result, given that null hypothesis is true
also known as observed level of significane
how to use p-value in making decision of whether to reject null hypothesis
Draw a diagram – it is the area more extreme than our test statistic, i.e. for the last example, p-value is P(Z>2.46).
Small p-value is evidence against the null hypothesis. For 5% chance of error, we set small to be
if p-value is smaller than α, then we will reject null hypothesis; get same conclusion from p-value and rejection region methods.
If p value is greater than or equal to α, do not reject null hypothesis
Describe one tailed test
If the alternative hypothesis is “”
This is a one tailed test
Rejection region will be in either upper or lower tail
P-value is the probability of getting a more extreme result
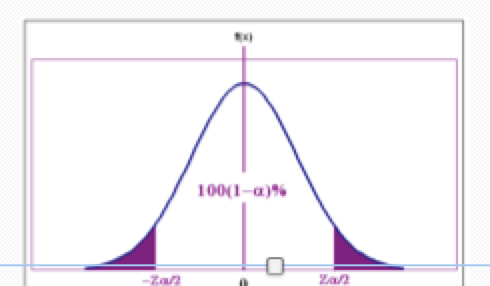
describe two tailed test
If the alternative hypothesis is “≠”
This is a two tailed test
Rejection region needs to be split between both tails
P-value will include an absolute value – i.e. will be the probability of getting further away from the hypothesised mean on either side
if alternative is “≠“
Rejection Region will be Z+Zα/2
P-value will be P(Z>|T.S|)+P(Z
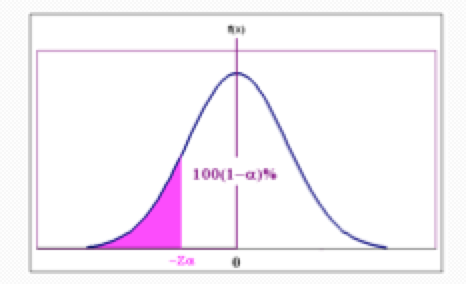
If alternative is “
Left tailed test
Rejection Region will be Z
P-value will be P(Z
So if alternative is “>“
Right tailed test
Rejection Region will be Z>+Zα
P-value will be P(Z>T.S)
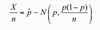
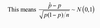

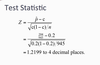


-
Probability63
-
Continuous probability distributions38
-
sampling and sampling distributions88
-
normal distribution1
-
Confidence Interval Estimation49
-
Hypothesis Testing51
-
Hypothesis testing for two means (independent samples, equal variances)32
-
Time series models7
-
Techniques for summarizing data15
-
descriptive statistics22
