DNA to RNA to Protein COPY Flashcards
(113 cards)
DNA replication enzymes
DNA replication enzymes form a large machine
Key proteins: helicase, SSB, primase, polymerase, ligase, and topoisomerase
Helicase unwinds DNA helix (needs ATP)
Single stranded binding protein (SSB) stabilizes single-stranded DNA
Primase synthesizes short complementary RNA primer (provides 3’ OH)
DNA polymerase synthesizes new DNA in a 5’ to 3’ direction ONLY
Ligase seals the break in DNA
Topoisomerase relieves twisting, turning, and knots in DNA (supercoiling)
single stranded binding protein
Single stranded binding protein (SSB) stabilizes single-stranded DNA
basically stabilizes single strands so do not tangle up, lots of thread all over the place need protein to prevent tying itself in knots**
Primer for DNA replication
Primase synthesizes short complementary RNA primer (provides 3’ OH)
RNA PRIMER than DNA polymerase adds onto primer
RNA primer means that stretch of RNA has to later be replaced by dna
for dna replication….
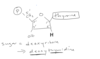
what kind of bonds are we breaking?
when breaking strands, breaking hydrogen bonds btwn two strands of dna helix
when use ligase to join together okazaki fragments, connecting parts of sugar phosphate backbone those are covalent bonds called phosphodiesterase bonds*; covalent bonds of sugar phosphate backbone
sugar phosphate sugar phosphate and bases connect to eachother in the middle*
middle image, pannel b if on edges 5’ end and blue sugar, when reffering to phosphate backbone is the blue, those bonds from one nucletide to the next are covalent bonds called phosphodiesterase bonds, what ligase catalyzes, puts together okazaki fragments through new phosphodiester bond* middle of DNA helix where bases connect to eachother and conenct through H bonds, A and T and G and C two strands connected down the middle with hydrogen bonds
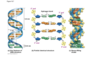
Ligase
connects Okazaki fragments on lagging strand, makes covalent bonds
each strand is covalently bonded= phosphodiesterase bonds*
covalent bonds of sugar phosphate backbone
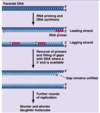
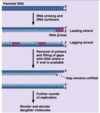
DNA replication mechanism
Enzymes first assemble at replication origin
Helicase → SSB → primase → DNA pol
Replication fork (Y-shaped junction) moves as DNA is replicated
Both new daughter strands are synthesized at the fork
Leading and Lagging strands
Leading strand synthesis is continuous (direction of replication fork movement)
Lagging strand synthesis is discontinuous (away from replication fork)
On lagging strand, a new RNA primer each ~200 bases in eukaryotes
Lagging strand DNA fragments = Okazaki fragments
RNA primer replaced with DNA by polymerase
Ligase seals the break in DNA between Okazaki fragments
Topoisomerase relieves twisting, turning, and knots in helix
DNA structure 1
DNA is a nucleotide polymer that underlies heredity
Usually double stranded
Each nucleotide has a pentose sugar, phosphate, and nitrogenous base
Alternating sugar and phosphate form helix backbone
Phosphates give DNA a negative charge
Bases are on the interior of the helix
DNA structure 2
Four nucleotides: adenine, guanine, thymine, cytosine (A, G, T, C)
Purines: A and G (two rings)
Pyrimidines: C and T (single ring)
Mnemonic: on a $1 bill, the pyramid is CUT
A pairs with T, two hydrogen bonds
G pairs with C, three hydrogen bonds
Amount of A = T, G = C in double stranded DNA (Chargaff ’s rule)
The two strands of the double helix are antiparallel (one 5’ to 3’, one 3’ to 5’)
Each turn (360°) = ten base pairs
Nucleoside = pentose sugar and nitrogenous base but no phosphate
Chargaff’s rule
Amount of A = T, G = C in double stranded DNA (Chargaff ’s rule)
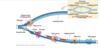
image description of DNA replication
ALWAYS added onto 3’ side, so on leading strand going into replication fork continuously, as zipper unzips that leading strand can just go go go
whereas on the lagging strand, the synthesis of DNA is discontinuous
so first of okazki fragments, so earlier stages red represents primer, dna polymerase making laggings trand and then DNA polymerase I replaces rna primer I with DNA, then DNA ligase makes phosphdiester bond that puts together fragmetns
DNA polymerase III is the work horse, used for most of the synthesis of DNA layign down of new DNA is done by DNA poly. III
DNA poly. I is specially equipped to replace the RNA primer with the equivalent DNA letters
Fidelity of DNA replication and proofreading
Errors are made spontaneously during DNA replication
Error rate is remarkably low (1 in 109)
“Proofreading” reduces errors and increases replication fidelity
DNA polymerase examines what it just synthesized
If pairing is wrong, polymerase pauses, removes mismatched base, resumes synthesis
Proofreading reflects exonuclease activity of polymerase (moves backwards, 3’ to 5’)
DNA polymerase can go backand cut out the wrong letter and replcae it with the correct letter, called an exonuclease function cutting out last letter put in
mutations and dna repair
Mutations occurs spontaneously, from replication errors, UV, X-rays, chemical mutagens
Spontaneous deamination (C → U), (methyl-C → T)
Spontaneous depurination (A and G base can be lost)
UV can crosslink T dimers
X-rays can cause double-stranded breaks
Some chemical mutagens increase rate of replication errors
Repair of DNA is facilitated by having two strands in helix
mutations and dna repair 2
- UV light can cross link thymine dimers, causing two thymies next to eachother on same strand to form extra bonds with eacother form a dimer and create a bulge in dna strand*** the way uv light is the road ot skin cancer** how UV light damages dna
Xrays are really bad news cause double stranded breaks, harder to repair
environmental chemicals, stuff we are exposed to can cause whole range of errors
Spontaneous deamination (C → U), (methyl-C → T), if look at chemical structures of letters sometimes turning one into another, if mess with one substituent on ring have different nitrogenous base, if alter the chmeistry of one base can turn it into another base
- Deamination literally means taking off the NH2 group and replacing it with a o double bonded

DNA repair mechanisms
Cells monitor DNA damage constantly and repair DNA
Cells have checkpoints to delay replication until damage is fixed
- Mismatch repair fixes mismatched base pairs after replication
- Base excision repair repairs one nucleotide (e.g., from deamination)
- Nucleotide excision repair fixes bulkier damage (e.g., crosslinked T dimers from UV)
- Double-strand break repair fixes a complete break in the double helix
general idea is so many enzymes devoted to repairing errors in DNA mutations or damage, and you can sort of think about them in terms of how big of a problem they address
ex. base excision reapir cuts out one and put right one in
nucletoide excision repair- bulkier damage, cuts out 10-20 so its like hwo big is the job have differnet enzymes etc.
if damage on one strand and enzyme come sina nd takes out huge chunk can often have complete repair, if just one strand has to be cut out then still have other strand which is complementary/record of what the right letters to go in should be
vs. Double strand break repair is what happens when have a complete break through both strands of DNA, what kind of damage get from xrays and that is somewhat salvagable but not completely issue is you are trying to glue together broken ends but usually lose some dna letters around the ends when you do that, there is a fix but it is not a perfect fix**
If you have mutations with DNA repair systems, you can really really have problems*
ribozymes
Can catalyze reactions, so supports can have reproducing primitive bits of RNA considered earliest lief forms- rna world
A few RNAs can acts as enzymes
RNA enzyme = ribozyme
Example: self-splicing intron
Catalytic ability of RNA supports RNA world hypothesis (RNA came first)
snRNPs
snRNPs = small nuclear RiboNucleoProtein complexes
snRNPs contain snRNAs (small nuclear RNAs)
mash up of rna and protein that do splicing* sp evidence of rna serving a catalytic role* rna world, point is its not just protein that catalyzes spelicing there is some rna in there also
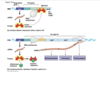
initation of translation
mRNA has on it start codon* AUG and hte first trna carrying the met attaches htere, 3’ UAC 5’
then large ribosomal subunit comes on top, everythign comes together around tnra and mrna
mrna what we just made through transcription, if go along mrna 5’ to 3’ three letters at a time, starting with AUG those are the codons
so codons are made of mrna, and the codons code for amino acids
trna= actually bring over hte amino acids needed according to code, tRNA has the anticodon of hte codon on mrna, so the compliment!
anticodon is complimentary to codon, but matching up of letters is also antiparalllel** codon 5’ to 3’ AUG, but anticodon is 3’ to 5’, 5; end of anticodon above 3’ end of codon, so sometimes they will say which anticodon goes with aug* answer choices will all be written 5’ to 3’, they would label it but correct answer to what anticodon is aug is CAU**** can seem wrong because its backwards** be very careful which is 5’ ends and 3’ end
first trna is in P site
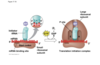
translation elognation
- new trna coming into A site, A for amino acid, next for amino acid comes into that site
- peptide bond formation, whole polypeptide chain in p site jumps over on top of new guy
- 6 oclock, whole chain now held on top of trna at A site temporarily, but then you need step three translocation where everything slides over
- 9 oclock, empty trna gets kicked out of exit site, to go pick up amino acid again for future; meanwhil in P site trna holding growing polypeptide chain, A site now empty so can now go back aroudn to 12 oclock and another trna with another amino acid can come in and keep elongation process going
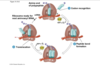
translation: termination
UGA, UAA, UAG
You go away, You are away, You are gone
**stop codons can be called amber* an amber codon is the same thing as a stop codon, weird terminology they love***
so when get to a stop codon, no trna but protein called release factor that binds to stop codon and causes the release of the polypeptide, trna and mrna, everythign is released and ribosome comes apart

energy for translation…..
KNOW FOR TRANSLATION GTP, translocation involves GTP, final step of termination invovles GTP*** remember which steps require energy

proteins are synthesized ….
N to C****
first amino acids to come off hte ribosome or the end that is made first is the amino end***
as each additional amino acid is beign added hte synthesis is proceeding toward carboxy end of peptide**
so if you have a problem, some mutaiton related problem in middle, amino end may be fine, like if shift in reading frame screw with entire amino acid, more liekly to have problem going toward carboxy, carboxy side is more screwed up because made later*
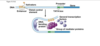
Cytoplasmic vs secreted and transmembrane protiens
- Cytoplasmic proteins are translated on free ribosomes
- Secreted and transmembrane proteins are translated on rough ER
- Secreted proteins and transmembrane proteins have signal peptide
- Signal peptide causes ribosome to pause translation, dock on rough ER
- Translation resumes, protein inserted into rough ER during translation
- Signal peptide is subsequently cleaved off protein
signal peptide= mailing label, part of amino acid sequence, series of amino acid at the terminus, but cell responds to it as a diretive to send the growing peptide to the membrane of the ER so peptide can go into ER and then proceed through that endo membrane system and then end up three fates: exocytosis from cell, inserted into plasma membrane or sent to a lysozome*
Post-translational modification
Once proteins leave the ribosome they can be modified further
Modifications can affect protein activity and function
Disulfide bonds for extracellular proteins (S-S bonds formed by cysteines)
Phosphorylation can regulate activity
Kinases add P
Phosphatases remove P
Glycosylation (add sugars in ER and Golgi)= after protein itself is made all sorts of ways like adding sugar groups, proteins can be modified
Proteolytic processing (e.g., zymogens)